When updating a document with the index API, we read the original document, make our changes, and then reindex the whole document in one go. The most recent indexing request wins: whichever document was indexed last is the one stored in Elasticsearch. If somebody else had changed the document in the meantime, their changes would be lost.
index API를 사용하여 document를 업데이트하는 경우, 원래의 document를 읽고, 변경을 하고, 그리고 나서 한번에 전체 document 를 재색인 한다. 가장 최근의 색인 request가 저장된다. 마지막으로 색인된 document가 Elasticsearch에 한번 저장된다. 누군가 그 사이에 document를 변경했다면, 그 변경 사항은 사라진다.
Many times, this is not a problem. Perhaps our main data store is a relational database, and we just copy the data into Elasticsearch to make it searchable. Perhaps there is little chance of two people changing the same document at the same time. Or perhaps it doesn’t really matter to our business if we lose changes occasionally.
많은 경우, 이런 상황은 문제가 되지 않는다. 아마 주 데이터의 저장소는 RDB이고, 검색 가능하도록 그 데이터를 Elasticsearch로 복사할 뿐이다. 아마도 두 사람이 동일한 document를 동시에 변경하는 경우는 거의 없을 것이다. 경우에 따라, 변경 사항이 사라지는 경우가 있겠지만, 크게 문제가 되지 않는다.
But sometimes losing a change is very important. Imagine that we’re using Elasticsearch to store the number of widgets that we have in stock in our online store. Every time that we sell a widget, we decrement the stock count in Elasticsearch.
그러나, 때때로 변경 사항을 잃어 버린 것이, _매우 중요할_ 수도 있다. Elasticsearch를 온라인 상점에서 재고 상품의 수를 저장하는데 사용하고 있다고 가정해 보자. 상품을 팔 때마다 Elasticsearch에서 재고 수를 감소시켜야 한다.
One day, management decides to have a sale. Suddenly, we are selling several widgets every second. Imagine two web processes, running in parallel, both processing the sale of one widget each, as shown in Figure 7, “동시성 제어가 없는 경우의 결과”.
어느 날 관리자가 sale을 하기로 했다. 갑자기 매초마다 여러 가지 상품이 팔릴 것이다. 동시에 동작하고 있는, 두 개의 web 프로세스를 생각해 보자. Figure 7, “동시성 제어가 없는 경우의 결과”에서 보여지는 것처럼, 둘 모두 하나의 상품에 대한 판매를 각각 진행하고 있다.
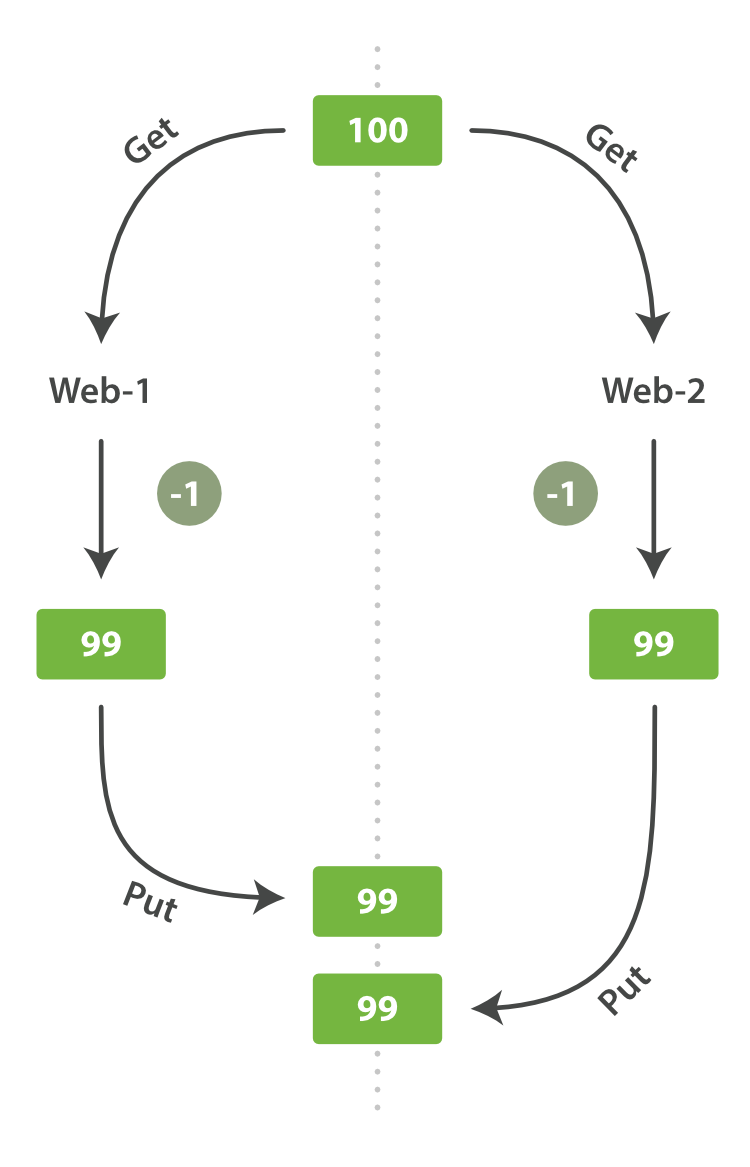
The change that web_1 made to the stock_count has been lost because web_2 is unaware that its copy of the stock_count is out-of-date. The result is that we think we have more widgets than we actually do, and we’re going to disappoint customers by selling them stock that doesn’t exist.
web_2 가 재고 수(stock_count) 복사본이 예전 상태임을 알지 못하기 때문에, 재고 수(stock_count) 에 대한 web_1 의 변화가 사라졌다. 결과적으로, 실제로 가지고 있는 것보다 더 많은 상품이 있다고 생각하여, 존재하지 않는 상품을 판매하여, 고객을 실망시킬 것이다.
The more frequently that changes are made, or the longer the gap between reading data and updating it, the more likely it is that we will lose changes.
변화가 더 자주 발생할수록, 데이터를 읽는 것과 업데이트 사이에 간격이 더 길수록, 변경 사항이 사라질 가능성은 더 많아진다.
In the database world, two approaches are commonly used to ensure that changes are not lost when making concurrent updates:
데이터베이스의 세계에서, 동시에 업데이트가 이루어지는 경우에, 변경 사항이 사라지지 않을 것을 보장하기 위해, 흔히 사용되는 두 가지 방법이 있다.
- 비관적인 동시성 제어(Pessimistic concurrency control)
Widely used by relational databases, this approach assumes that conflicting changes are likely to happen and so blocks access to a resource in order to prevent conflicts. A typical example is locking a row before reading its data, ensuring that only the thread that placed the lock is able to make changes to the data in that row.
RDB에서 널리 사용된다. 이 접근 방식은 변경 사항이 충돌할 가능성이 있다고 추정한다. 그래서 충돌을 막기 위해 특정 resource에 대한 접근을 막는다. 전형적인 예는, 데이터를 읽기 전에 row를 잠그는 것이다. 데이터를 잠근 thread만 해당 row에 있는 데이터를 바꿀 수 있도록 하는 것이다.
- 낙관적인 동시성 제어(Optimistic concurrency control)
Used by Elasticsearch, this approach assumes that conflicts are unlikely to happen and doesn’t block operations from being attempted. However, if the underlying data has been modified between reading and writing, the update will fail. It is then up to the application to decide how it should resolve the conflict. For instance, it could reattempt the update, using the fresh data, or it could report the situation to the user.
Elasticsearch에서 사용된다. 이 접근 방식은 충돌은 발생하지 않을 것이라 가정한다. 그래서, 시도되는 연산을 막지 않는다. 그러나, 읽기와 쓰기 사이에 기본 데이터가 변경되면, 업데이트는 실패한다. 충돌을 해결하는 방법은 응용프로그램에 달려 있다. 예를 들어 새로운 데이터를 이용하여 업데이트를 다시 시도하거나, 사용자에게 상황을 보고할 수 있다.
'2.X > 1. Getting Started' 카테고리의 다른 글
| 1-03-07. Creating a New Document (0) | 2017.10.01 |
|---|---|
| 1-03-08. Deleting a Document (0) | 2017.10.01 |
| 1-03-10. Optimistic Concurrency Control (0) | 2017.10.01 |
| 1-03-11. Partial Updates to Documents (0) | 2017.10.01 |
| 1-03-12. Retrieving Multiple Documents (0) | 2017.10.01 |