We’ve said that Elasticsearch can cope when nodes fail, so let’s go ahead and try it out. If we kill the first node, our cluster looks like Figure 6, “node 하나를 kill한 후의 cluster”.
node에 장애가 발생할 경우, Elasticsearch는 대응할 수 있다고 했는데, 한 번 test해 보자. cluster의 첫 번째 node를 kill하면, Figure 6, “node 하나를 kill한 후의 cluster”처럼 보일 것이다.
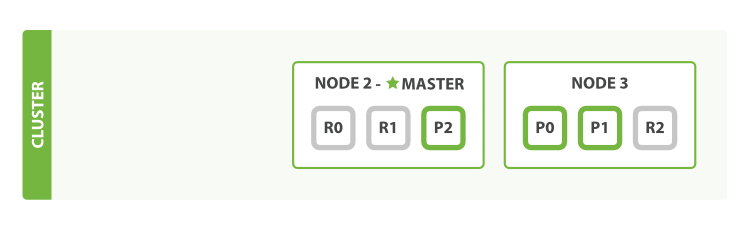
The node we killed was the master node. A cluster must have a master node in order to function correctly, so the first thing that happened was that the nodes elected a new master: Node 2.
kill한 node는 master node였다. cluster가 올바르게 동작하기 위해서는, 반드시 master를 가져야 한다. 그래서 첫 번째로 일어난 일은, 새로운 master(Node 2)를 선출하는 것이었다.
Primary shards 1 and 2 were lost when we killed Node 1, and our index cannot function properly if it is missing primary shards. If we had checked the cluster health at this point, we would have seen status red: not all primary shards are active!
primary shard 1 과 2 는 Node 1 을 kill 했을 때 손실되었고, primary shard를 잃어버렸다면 index는 제대로 동작할 수 없다. 이 시점에 cluster health를 확인해 보면, red 라는 상태(모든 primary가 정상인 것은 아니다)를 볼 수 있다.
Fortunately, a complete copy of the two lost primary shards exists on other nodes, so the first thing that the new master node did was to promote the replicas of these shards on Node 2 and Node 3 to be primaries, putting us back into cluster health yellow. This promotion process was instantaneous, like the flick of a switch.
다행히도, 잃어버린 primary shard 두 개의, 완벽한 복사본이 다른 node에 존재한다. 그래서 새로운 master node가 한 첫 번째 작업은, Node 2 와 Node 3 에 있는, 이들 shard의 replica를 primary로 승격시키는 것이다. 그래서 cluster health가 yellow 로 바뀐다. 이 승격 프로세스는 작업은 순식간(스위치를 켜는 것처럼)이다.
So why is our cluster health yellow and not green? We have all three primary shards, but we specified that we wanted two replicas of each primary, and currently only one replica is assigned. This prevents us from reaching green, but we’re not too worried here: were we to kill Node 2 as well, our application could still keep running without data loss, because Node 3 contains a copy of every shard.
그럼 왜 cluster health는 green 이 아니고, yellow 인가? 모두 3개의 primary shard를 가지고 있고, 각 primary당 2개의 replica를 지정하였으나, 현재는 1개의 replica만 할당되어 있다. 이것이 green 이 되지 못하는 이유이지만, 이것 때문에 너무 걱정하지 않아도 된다. Node 2 가 kill 되더라도, Node 3 이 모든 node의 복사본을 가지고 있기 때문에, 응용프로그램은 여전히 데이터 손실 없이 동작할 수 있다.
If we restart Node 1, the cluster would be able to allocate the missing replica shards, resulting in a state similar to the one described in Figure 5, “number_of_replica 를 2로 증가”. If Node 1 still has copies of the old shards, it will try to reuse them, copying over from the primary shard only the files that have changed in the meantime.
Node 1 을 다시 시작하면, cluster는 잃어버린 replica shard가 할당될 것이고, Figure 5, “number_of_replica 를 2로 증가”에서 묘사된 것과 유사한 상태가 될 것이다. Node 1 이 여전히 기존 shard의 복사본을 가지고 있다면, primary shard에서 그 동안 변경된 파일만을 복사하여, 그것을 재 사용하려 할 것이다.
By now, you should have a reasonable idea of how shards allow Elasticsearch to scale horizontally and to ensure that your data is safe. Later we will examine the life cycle of a shard in more detail.
이제 여러분은 Elasticsearch에서 shard를 수평확장 하는 방법과, 데이터가 안전하다는 것을 보장하는 방법에 대해 이해하고 있어야 한다. 나중에 shard의 life cycle에 대해 더 자세히 살펴보겠다.
'2.X > 1. Getting Started' 카테고리의 다른 글
| 1-02-4. Add Failover (0) | 2017.10.01 |
|---|---|
| 1-02-5. Scale Horizontally (0) | 2017.10.01 |
| 1-03. Data In, Data Out (0) | 2017.10.01 |
| 1-03-01. What Is a Document? (0) | 2017.10.01 |
| 1-03-02. Document Metadata (0) | 2017.10.01 |