What about scaling as the demand for our application grows? If we start a third node, our cluster reorganizes itself to look like Figure 4, “세 개의 node를 가진 cluster(shard는 부하를 분산하기 위하여 재할당되었다)”.
응용프로그램에 대한 수요가 증가함에 따라, 확장하면 어떠할까? 세 번째 node를 시작하면, cluster는 Figure 4, “세 개의 node를 가진 cluster(shard는 부하를 분산하기 위하여 재할당되었다)”처럼 스스로를 인식할 것이다.
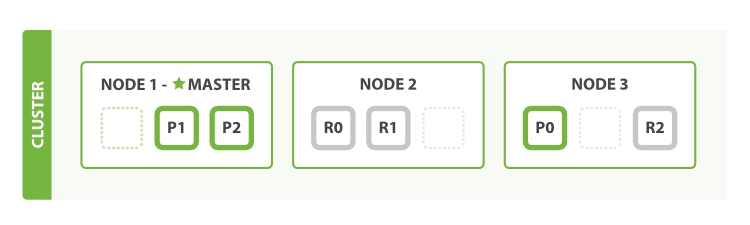
One shard each from Node 1 and Node 2 have moved to the new Node 3, and we have two shards per node, instead of three. This means that the hardware resources (CPU, RAM, I/O) of each node are being shared among fewer shards, allowing each shard to perform better.
Node 1 과 Node 2 에서, 각각 하나의 shard가 새로운 Node 3 으로 이동하였고, 각 node는 3개 대신 2개의 shard를 가지게 되었다. 즉, 각 shard가 더 잘 수행될 수 있도록, 각 node의 H/W 자원(CPU, RAM, I/O)이 더 작은 수의 shard 사이에서 공유되고 있다.
A shard is a fully fledged search engine in its own right, and is capable of using all of the resources of a single node. With our total of six shards (three primaries and three replicas), our index is capable of scaling out to a maximum of six nodes, with one shard on each node and each shard having access to 100% of its node’s resources.
shard는 그 자체로 충분한 검색 엔진이고, 단일 node의 자원 모두를 사용할 수 있다. 모두 6개의 shard(3개의 primary와 3개의 replica)를 가진 index는, 각 node당 하나의 shard를 가지고, 각 shard는 각 node의 자원을 100% 활용할 수 있는, 최대 6개의 node로 확장할 수 있다.
Then Scale Some Moreedit
But what if we want to scale our search to more than six nodes?
하지만, 6개 이상의 node로 검색을 확장해야 한다면?
The number of primary shards is fixed at the moment an index is created. Effectively, that number defines the maximum amount of data that can be stored in the index. (The actual number depends on your data, your hardware and your use case.) However, read requests—searches or document retrieval—can be handled by a primary or a replica shard, so the more copies of data that you have, the more search throughput you can handle.
primary shard의 수는 index가 생성되는 순간에 고정된다. 사실상, 그 수는 index에 저장될_ 수 있는 데이터의 최대값을 정의한다. (실제 수는 데이터, H/W, 사용 사례에 따라 달라진다.) 그러나, 읽기 request(검색 또는 document 검색)는 primary 또는 replica에 의해 처리된다. 따라서 가지고 있는 데이터의 복사본이 많을수록, 더 많은 검색을 처리할 수 있다.
The number of replica shards can be changed dynamically on a live cluster, allowing us to scale up or down as demand requires. Let’s increase the number of replicas from the default of 1 to 2:
replica shard의 수는 동작하는 cluster에서, 동적으로 변경(수요에 따라 확장 또는 축소)할 수 있다. replica의 수를 기본값인 1 에서 2 로 증가시켜 보자.
PUT /blogs/_settings { "number_of_replicas" : 2 }
As can be seen in Figure 5, “number_of_replica 를 2로 증가”, the blogs index now has nine shards: three primaries and six replicas. This means that we can scale out to a total of nine nodes, again with one shard per node. This would allow us to triple search performance compared to our original three-node cluster.
Figure 5, “number_of_replica 를 2로 증가”에서 보듯이, blogs index는 이제 9개의 shard(3개의 primary와 6개의 replica)를 가지고 있다. 즉, node당 하나의 shard를 가지도록 하면, 총 9개의 node로 수평확장 할 수 있다. 이렇게 되면, 원래의 3개의 node를 가진 cluster와 비교했을 경우, 3배 의 검색 성능을 가지게 된다.
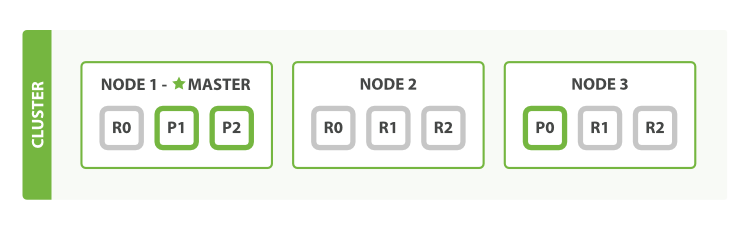
Of course, just having more replica shards on the same number of nodes doesn’t increase our performance at all because each shard has access to a smaller fraction of its node’s resources. You need to add hardware to increase throughput.
물론, 각 shard는 node 자원의 더 작은 부분을 차지 하기 때문에, 동일한 수의 node가 더 많은 replica shard를 가진다고 해서, 성능이 향상되는 것은 아니다. 처리량을 늘리기 위해서는 H/W를 추가해야 한다.
But these extra replicas do mean that we have more redundancy: with the node configuration above, we can now afford to lose two nodes without losing any data.
그러나, 이러한 추가 replica는 더 많은 복사본을 가지고 있다는 것을 의미한다. 위에서의 node 구성으로, 두 개의 node를 잃어도 데이터 손실은 없다.
'2.X > 1. Getting Started' 카테고리의 다른 글
| 1-02-3. Add an Index (0) | 2017.10.01 |
|---|---|
| 1-02-4. Add Failover (0) | 2017.10.01 |
| 1-02-6. Coping with Failure (0) | 2017.10.01 |
| 1-03. Data In, Data Out (0) | 2017.10.01 |
| 1-03-01. What Is a Document? (0) | 2017.10.01 |