With the automatic refresh process creating a new segment every second, it doesn’t take long for the number of segments to explode. Having too many segments is a problem. Each segment consumes file handles, memory, and CPU cycles. More important, every search request has to check every segment in turn; the more segments there are, the slower the search will be.
매초마다 자동 refresh 프로세스가 새로운 segment를 생성하면, segment가 폭발적으로 증가하는 데에는 그리 오래 걸리지 않는다. 너무 많은 segment를 가지는 것이 문제이다. 각 segment는 file handle, 메모리, CPU를 소모한다. 더 중요한 것은 모든 검색 request가 모든 segment를 차례로 확인해야 한다는 것이다. segment가 많을수록 검색은 더 느려질 것이다.
Elasticsearch solves this problem by merging segments in the background. Small segments are merged into bigger segments, which, in turn, are merged into even bigger segments.
Elasticsearch는 이 문제를 background에서 segment를 병합하는 것으로 해결했다. 작은 segment는 더 큰 segment로 병합되고, 차례로 더 큰 segment조차 병합된다.
This is the moment when those old deleted documents are purged from the filesystem. Deleted documents (or old versions of updated documents) are not copied over to the new bigger segment.
이 시점이, 기존에 삭제되었던 document가 file system에서 제거되는 순간이다. 삭제된 document(또는 업데이트된 document의 기존 버전)는 새로운 더 큰 segment로 복사되지 않는다.
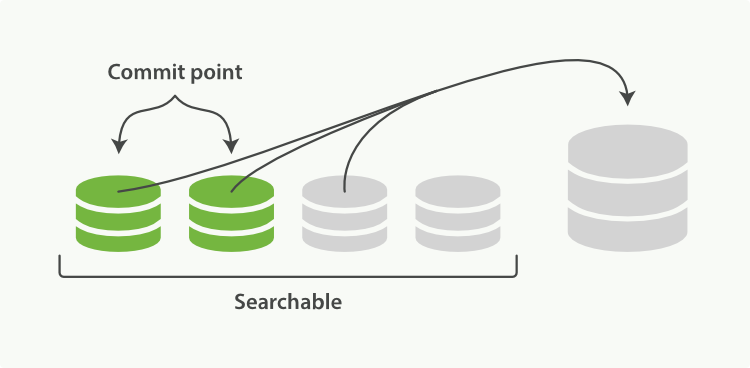
There is nothing you need to do to enable merging. It happens automatically while you are indexing and searching. The process works like as depicted in Figure 25, “더 큰 segment로 병합되는 프로세스에서, 두 개의 commit된 segment와 하나의 commit되지 않은 segment”:
이것은 색인하고 검색하는 동안 자동으로 발생하므로, 병합을 활성화하기 위해, 해야 할 것은 아무것도 없다. 이 프로세스는 Figure 25, “더 큰 segment로 병합되는 프로세스에서, 두 개의 commit된 segment와 하나의 commit되지 않은 segment”처럼 동작한다.
While indexing, the refresh process creates new segments and opens them for search.
색인 하는 동안, refresh 프로세스는 새로운 segment를 생성하고, 검색을 위해 그것을 연다.
The merge process selects a few segments of similar size and merges them into a new bigger segment in the background. This does not interrupt indexing and searching.
병합 프로세스는 비슷한 크기의 segment를 몇 개 선택하고, background에서 그것들을 새로운 더 큰 segment로 병합한다. 이것은 색인이나 검색에 영향을 끼치지 않는다.
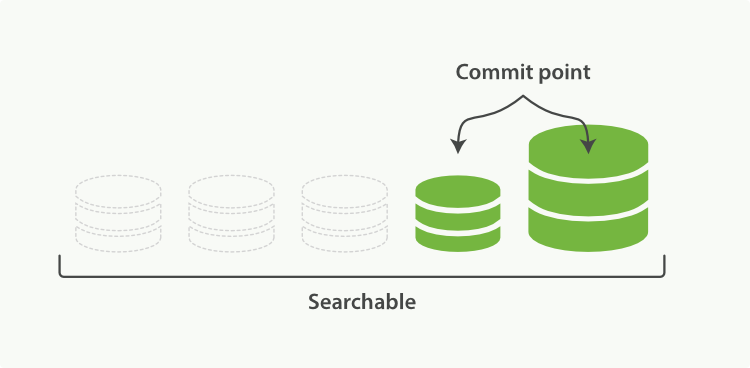
Figure 26, “병합이 완료되면, 기존의 segment는 삭제된다.” illustrates activity as the merge completes:
병합이 완료되었을 때, 동작은 Figure 26, “병합이 완료되면, 기존의 segment는 삭제된다.”과 같다.
The new segment is flushed to disk.
새로운 segment는 디스크로 flush된다.
A new commit point is written that includes the new segment and excludes the old, smaller segments.
새로운 commit point는, 새로운 segment를 포함하고, 기존의 혹은 더 작은 segment는 제외한 채로, 기록된다.
The new segment is opened for search.
새로운 segment는 검색을 위해 열린다.
The old segments are deleted.
기존의 segment는 삭제된다.
The merging of big segments can use a lot of I/O and CPU, which can hurt search performance if left unchecked. By default, Elasticsearch throttles the merge process so that search still has enough resources available to perform well.
큰 segment의 병합은 많은 I/O와 CPU를 사용할 수 있고, 방치할 경우, 검색 성능에 문제가 발생할 수 있다. 검색이 잘 수행되도록 충분한 자원을 확보하기 위해, 기본적으로 Elasticsearch는 병합 프로세스를 조절한다.
See Segments and Merging for advice about tuning merging for your use case.
사용 사례를 위해 병합의 세부 조정에 대한 조언은 Segments and Merging을 참고하자.
optimize APIedit
The optimize API is best described as the forced merge API. It forces a shard to be merged down to the number of segments specified in the max_num_segments parameter. The intention is to reduce the number of segments (usually to one) in order to speed up search performance.
optimize API는 강제 병합(forced merge) API 로서는 최고이다. max_num_segments 매개변수에 지정된, segment의 수 아래로, shard를 강제로 병합한다. 검색 성능의 향상을 위해, segment의 수를 줄이는 것(일반적으로 1)이 목적이다.
The optimize API should not be used on a dynamic index—an index that is being actively updated. The background merge process does a very good job, and optimizing will hinder the process. Don’t interfere!
optimize API는 동적 index(업데이트가 활발한 index)에는 사용되지 않는다. background 병합 프로세스는 매우 훌륭한 작업이고, 최적화는 그 프로세스를 방해한다. 방해하지 말자!
In certain specific circumstances, the optimize API can be beneficial. The typical use case is for logging, where logs are stored in an index per day, week, or month. Older indices are essentially read-only; they are unlikely to change.
어떤 매우 독특한 상황에서, optimize API는 유용할 수 있다. 전형적인 사용 사례는, log가 일, 주 또는 월별로 index에 저장되는, logging이다. 기존 index는 기본적으로 읽기 전용이다. 거의 변경되지 않는다.
In this case, it can be useful to optimize the shards of an old index down to a single segment each; it will use fewer resources and searches will be quicker:
이 경우에, 기존 index의 shard를 각각 하나의 segment로 최적화(optimize)하는 것은 유용할 수 있다. 자원을 거의 사용하지 않을 것이고, 검색은 더 빨라질 것이다.
| index의 각 shard를 하나의 segment로 병합한다. |
Be aware that merges triggered by the optimize API are not throttled at all. They can consume all of the I/O on your nodes, leaving nothing for search and potentially making your cluster unresponsive. If you plan on optimizing an index, you should use shard allocation (see Migrate Old Indices) to first move the index to a node where it is safe to run.
optimize API가 전혀 조절되지 않아, 병합이 촉발되는 것을 주의하자. node의 I/O를 모두 사용할 수 있다. 검색도 안되고 잠재적으로 cluster가 반응하지 않을 수 있다. index를 최적화하려는 경우, 안전하게 동작할 수 있는 node로 index를 먼저 옮기기 위해, shard 할당(Migrate Old Indices 참조)을 사용해야 한다.
'2.X > 1. Getting Started' 카테고리의 다른 글
| 1-11. Inside a Shard (0) | 2017.09.30 |
|---|---|
| 1-11-1. Making Text Searchable (0) | 2017.09.30 |
| 1-11-2. Dynamically Updatable (0) | 2017.09.30 |
| 1-11-3. Near Real-Time Search (0) | 2017.09.30 |
| 1-11-4. Making Changes Persistent (0) | 2017.09.30 |