The next problem that needed to be solved was how to make an inverted index updatable without losing the benefits of immutability? The answer turned out to be: use more than one index.
해결해야 할 다음 문제는, 불변성의 장점을 잃지 않고, inverted index를 업데이트 가능하도록 만드는 방법이다. 답은 하나 이상의 index를 사용하는 것이다.
Instead of rewriting the whole inverted index, add new supplementary indices to reflect more-recent changes. Each inverted index can be queried in turn—starting with the oldest—and the results combined.
전체 inverted index를 다시 쓰는 대신, 최근의 변경 사항을 반영할 수 있는, 새로운 추가적인 indices를 추가하는 것이다. 오래 된 것부터 시작해서, 각 inverted index를 차례대로 query하고, 결과를 조합하는 것이다.
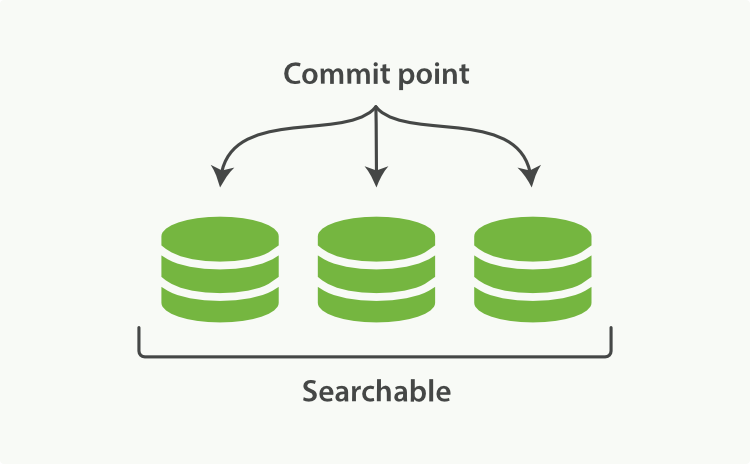
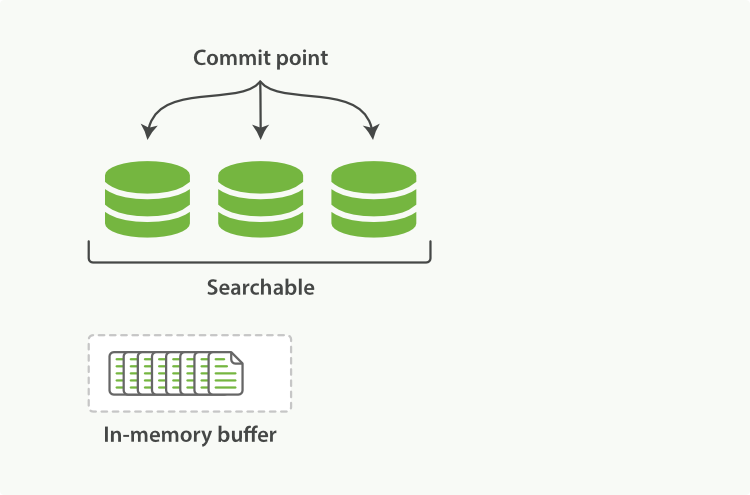
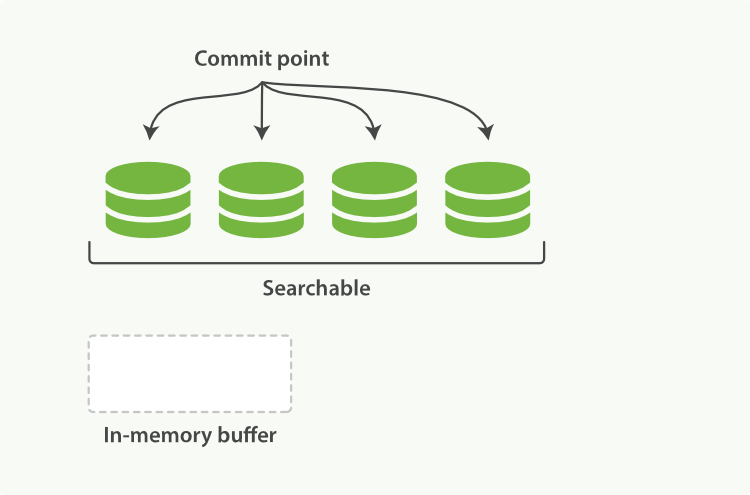
Lucene, the Java libraries on which Elasticsearch is based, introduced the concept of per-segment search. A segment is an inverted index in its own right, but now the word index in Lucene came to mean a collection of segments plus a commit point—a file that lists all known segments, as depicted in Figure 16, “하나의 commit point와 3개의 segment를 가진 Lucene index”. New documents are first added to an in-memory indexing buffer, as shown in Figure 17, “in-memory buffer에 commit할 준비가 된, 새로운 document를 가진 Lucene index”, before being written to an on-disk segment, as in Figure 18, “commit 후에, 새로운 segment는 commit point에 추가되고, buffer는 지워진다”
Elasticsearch의 기반이 되는 Java library인, Lucene은 segment별(per-segment) 검색 이라는 개념을 소개하고 있다. segment 는 그 자체로 inverted index이다. 그러나, 지금 Lucene에서 index 라는 단어는,Figure 16, “하나의 commit point와 3개의 segment를 가진 Lucene index”에서 묘사된 것처럼, segment의 집합(collection of segments) 에 commit point(알려진 segment 모두를 나열한 파일)를 추가한 것을 의미하게 되었다. 새로운 document는, Figure 18, “commit 후에, 새로운 segment는 commit point에 추가되고, buffer는 지워진다”처럼, on-disk segment에 쓰여지기 전에, Figure 17, “in-memory buffer에 commit할 준비가 된, 새로운 document를 가진 Lucene index”처럼 in-memory indexing buffer에 먼저 추가된다.
A per-segment search works as follows:
segment별(per-segment) 검색은 다음과 같이 동작한다.
New documents are collected in an in-memory indexing buffer. See Figure 17, “in-memory buffer에 commit할 준비가 된, 새로운 document를 가진 Lucene index”.
Figure 17, “in-memory buffer에 commit할 준비가 된, 새로운 document를 가진 Lucene index”처럼, 새로운 document는 in-memory indexing buffer에 수집된다.
Every so often, the buffer is commited:
가끔, buffer는 commit 된다.
A new segment—a supplementary inverted index—is written to disk.
새로운 segment(추가 inverted index)가 디스크에 기록된다.
A new commit point is written to disk, which includes the name of the new segment.
새로운 commit point 가 디스크에 기록된다. 이것은 새로운 segment의 이름을 포함하고 있다.
The disk is fsync’ed—all writes waiting in the filesystem cache are flushed to disk, to ensure that they have been physically written.
디스크는 fsync 된다. 물리적으로 기록되었다는 것을 보장하기 위해, file-system cache에서 대기하는 모든 쓰기는, 디스크에 flush된다.
The new segment is opened, making the documents it contains visible to search.
segment가 가지고 있는 document가 검색 시에 보이도록 하기 위해, 새로운 segment는 열린다.
The in-memory buffer is cleared, and is ready to accept new documents.
in-memory buffer는 지워지고, 새로운 document를 받아들일 준비를 한다.
When a query is issued, all known segments are queried in turn. Term statistics are aggregated across all segments to ensure that the relevance of each term and each document is calculated accurately. In this way, new documents can be added to the index relatively cheaply.
query가 실행되면, 알려진 모든 segment는 차례로 query된다. 각 단어와 각 document의 relevance가 정확하게 계산되도록, 단어 통계는 모든 segment에 걸쳐 aggregation된다. 이러한 방식으로, 새로운 document는 비교적 작은 비용으로, index에 추가될 수 있다.
Deletes and Updatesedit
Segments are immutable, so documents cannot be removed from older segments, nor can older segments be updated to reflect a newer version of a document. Instead, every commit point includes a .del file that lists which documents in which segments have been deleted.
segment는 불변이다. 따라서, document는 기존 segment에서 제거하거나, document의 새로운 버전을 반영하기 위해, 업데이트될 수 없다. 대신, 모든 commit point는, segment에서 삭제된 document의 목록을 가진 .del 파일을 포함하고 있다.
When a document is "deleted", it is actually just marked as deleted in the .del file. A document that has been marked as deleted can still match a query, but it is removed from the results list before the final query results are returned.
document가 "삭제" 되면, 실제로는 .del 파일에 삭제되었다고 표시 될 뿐이다. 삭제되었다고 표시된 document는 여전히 query에 일치할 수 있다. 그러나, query 결과가 반환되기 전, 마지막에 결과 목록에서 제거된다.
Document updates work in a similar way: when a document is updated, the old version of the document is marked as deleted, and the new version of the document is indexed in a new segment. Perhaps both versions of the document will match a query, but the older deleted version is removed before the query results are returned.
document 업데이트 작업도 유사한 방식이다. document가 업데이트되면, document의 기존 버전은 삭제되었다고 표시된다. 그리고 document의 새로운 버전은 새로운 segment에 색인된다. 아마도 document의 두 버전 모두 query에 일치할 것이다. 그러나 기존의 삭제된 버전은, query 결과가 반환되기 전에, 제거된다.
In Segment Merging, we show how deleted documents are purged from the filesystem.
Segment Merging에서, document를 삭제하고 file system에서 제거되는 방법에 대하여 이야기 할 것이다.
'2.X > 1. Getting Started' 카테고리의 다른 글
| 1-11. Inside a Shard (0) | 2017.09.30 |
|---|---|
| 1-11-1. Making Text Searchable (0) | 2017.09.30 |
| 1-11-3. Near Real-Time Search (0) | 2017.09.30 |
| 1-11-4. Making Changes Persistent (0) | 2017.09.30 |
| 1-11-5. Segment Merging (0) | 2017.09.30 |