With the development of per-segment search, the delay between indexing a document and making it visible to search dropped dramatically. New documents could be made searchable within minutes, but that still isn’t fast enough.
segment별 검색의 개발로, document의 색인과 검색 시에 보이도록 하는 것 사이에 지연이 크게 발생한다. 새로운 document는 수분 내에 검색이 가능하지만, 아직 충분히 빠르지는 않다.
The bottleneck is the disk. Commiting a new segment to disk requires an fsync to ensure that the segment is physically written to disk and that data will not be lost if there is a power failure. But an fsync is costly; it cannot be performed every time a document is indexed without a big performance hit.
병목현상은 디스크에서 발생한다. 디스크에 새로운 segment를 commit하는 것은, segment가 물리적으로 디스크에 저장되었고, 데이터가 정전이 있더라도 손실이 없다는 것을 보장하기 위해, fsync를 요구한다. 그러나, fsync 는 많은 비용이 든다. document가 색인될 때마다, 큰 성능 저하 없이 수행될 수는 없다.
What was needed was a more lightweight way to make new documents visible to search, which meant removing fsync from the equation.
새로운 document가 검색 시에 보이도록 하기 위해 필요한 것은 더 가벼운 방식이다. 즉, 이 상황에서 fsync 를 제거해야 한다.
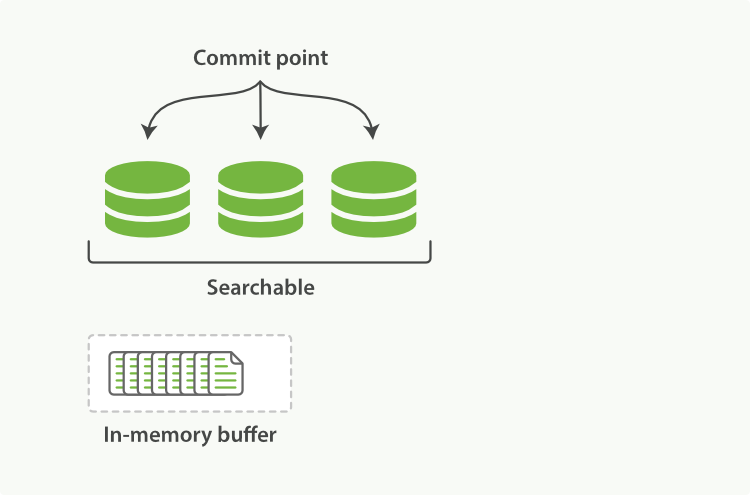
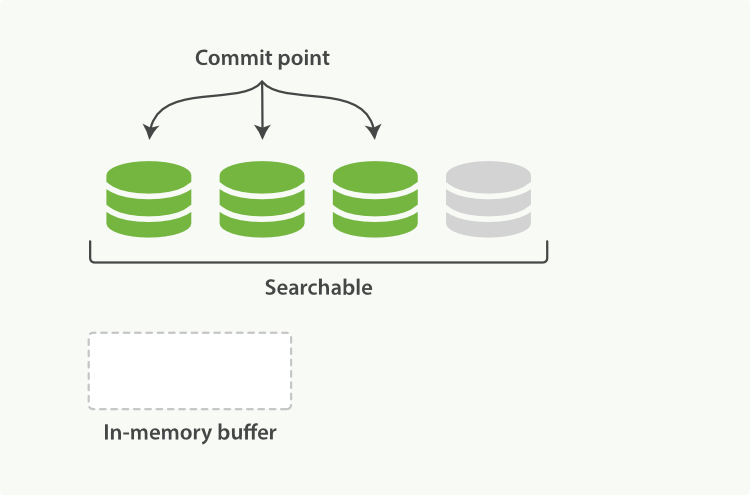
Sitting between Elasticsearch and the disk is the filesystem cache. As before, documents in the in-memory indexing buffer (Figure 19, “in-memory buffer에 새로운 document를 가진 Lucene의 index”) are written to a new segment (Figure 20, “buffer의 내용은 segment에 쓰여진다. 이는 검색 가능하지만, 아직 commit되지 않았다.”). But the new segment is written to the filesystem cache first—which is cheap—and only later is it flushed to disk—which is expensive. But once a file is in the cache, it can be opened and read, just like any other file.
Elasticsearch와 디스크 사이에 있는 것은 file-system cache이다. 이전과 마찬가지로, in-memory indexing buffer에 있는 document(Figure 19, “in-memory buffer에 새로운 document를 가진 Lucene의 index”)는 새로운 segment에 쓰여진다(Figure 20, “buffer의 내용은 segment에 쓰여진다. 이는 검색 가능하지만, 아직 commit되지 않았다.”). 그러나, 새로운 segment는, 비용이 적게 드는, file-system cache에 먼저 쓰여진다. 그리고 나중에 비용이 많이 드는 디스크에 flush된다. 그러나, cache에 존재하는 파일은 다른 파일과 마찬가지로 열릴 수 있고 읽힐 수 있다.
Lucene allows new segments to be written and opened—making the documents they contain visible to search—without performing a full commit. This is a much lighter process than a commit, and can be done frequently without ruining performance.
Lucene은, 그들이 포함하고 있는 document를 검색 시에 보이도록 하기 위해, 전체적인 commit 없이, 새로운 segment를 열고 쓸 수 있다. 이것은 commit보다 훨씬 더 가벼운 프로세스이고, 성능 저하 없이, 자주 할 수 있다.
refresh APIedit
In Elasticsearch, this lightweight process of writing and opening a new segment is called a refresh. By default, every shard is refreshed automatically once every second. This is why we say that Elasticsearch has near real-time search: document changes are not visible to search immediately, but will become visible within 1 second.
Elasticsearch에서, 새로운 segment를 열고 쓰는, 이 가벼운 프로세스는 refresh 라 불려진다. 기본적으로, 모든 shard는 매초마다 자동으로 refresh된다. 이것이 Elasticsearch가 거의(near) 실시간 검색이라 말하는 이유이다. document의 변경은, 검색에서 즉시 보이지 않는다. 그러나 1초내에 보이게 될 것이다.
This can be confusing for new users: they index a document and try to search for it, and it just isn’t there. The way around this is to perform a manual refresh, with the refresh API:
이는 새로운 사용자에게 혼란스러울 것이다. document를 색인하고 그것을 검색하려고 시도한다. 그런데, 거기에 없다. 이 경우에는 refresh API를 사용해, 수동으로 refresh를 하자.
| 모든 indices를 refresh. |
|
|
While a refresh is much lighter than a commit, it still has a performance cost. A manual refresh can be useful when writing tests, but don’t do a manual refresh every time you index a document in production; it will hurt your performance. Instead, your application needs to be aware of the near real-time nature of Elasticsearch and make allowances for it.
refresh가 commit보다 훨씬 저렴하긴 하지만, 여전히 성능 비용을 가진다. 수동 refresh는 쓰기 test에 유용할 수 있다. 그러나, 제품에서 document를 색인할 때마다, 수동으로 refresh하지는 말자. 성능에 좋지 않다. 응용프로그램은 Elasticsearch가 거의 실시간이라는 본질을 인식하고, 그것을 감안해야 한다.
Not all use cases require a refresh every second. Perhaps you are using Elasticsearch to index millions of log files, and you would prefer to optimize for index speed rather than near real-time search. You can reduce the frequency of refreshes on a per-index basis by setting the refresh_interval:
모든 사용 사례에서, 매초마다 refresh를 요구하지는 않는다. 아마도, 수백만 건의 로그 파일을 색인하기 위해, Elasticsearch를 사용한다면, 거의 실시간인 검색 보다는, 색인 속도 최적화가 더 나을 것이다. refresh_interval 을 설정하여, index별 refresh 빈도를 줄일 수 있다.
| 매 30초마다 |
The refresh_interval can be updated dynamically on an existing index. You can turn off automatic refreshes while you are building a big new index, and then turn them back on when you start using the index in production:
refresh_interval 은 기존의 index에서 동적으로 업데이트될 수 있다. 새로 커다란 index를 생성하는 동안, 자동 refresh를 끌 수 있다. 그리고 제품에서 index를 사용할 때 다시 켤 수 있다.
PUT /my_logs/_settings { "refresh_interval": -1 }PUT /my_logs/_settings { "refresh_interval": "1s" }
| 자동 refresh를 비활성화. |
| 매초마다 자동으로 refresh. |
The refresh_interval expects a duration such as 1s (1 second) or 2m (2 minutes). An absolute number like 1 means 1 millisecond--a sure way to bring your cluster to its knees.
refresh_interval 은 1s(1초) 나 2m(2분) 같은 기간 을 기대한다. 1 같은 절대적인 수는 1 millisecond 를 의미한다. cluster를 다운시키는 가장 확실한 방법이다
'2.X > 1. Getting Started' 카테고리의 다른 글
| 1-11. Inside a Shard (0) | 2017.09.30 |
|---|---|
| 1-11-1. Making Text Searchable (0) | 2017.09.30 |
| 1-11-2. Dynamically Updatable (0) | 2017.09.30 |
| 1-11-4. Making Changes Persistent (0) | 2017.09.30 |
| 1-11-5. Segment Merging (0) | 2017.09.30 |