Without an fsync to flush data in the filesystem cache to disk, we cannot be sure that the data will still be there after a power failure, or even after exiting the application normally. For Elasticsearch to be reliable, it needs to ensure that changes are persisted to disk.
fsync 없이, filesystem cache에서 디스크로, 데이터를 flush하면, 정전 후에 또는 응용프로그램이 정상적으로 종료된 후에, 데이터가 거기 있다고 확신할 수 없다. 신뢰할 수 있는 Elasticsearch를 위해, 변경 사항이 디스크에 유지되도록 보장해야 한다.
In Dynamically Updatable Indices, we said that a full commit flushes segments to disk and writes a commit point, which lists all known segments. Elasticsearch uses this commit point during startup or when reopening an index to decide which segments belong to the current shard.
Dynamically Updatable Indices에서, full commit은 segment를 디스크에 flush하고, 알려진 모든 segment 목록인, commit point를 기록한다고 했다. Elasticsearch는 시작하는 동안이나, 현재 shard에 포함되는 segment를 결정하기 위해 index를 다시 여는 경우에, 이 commit point를 사용한다.
While we refresh once every second to achieve near real-time search, we still need to do full commits regularly to make sure that we can recover from failure. But what about the document changes that happen between commits? We don’t want to lose those either.
거의 실시간인 검색을 수행하기 위해, 매초마다 refresh를 하는 동안, 오류를 복구할 수 있는지를 보장하기 위해, 여전히 주기적으로 전체 commit을 해야 한다. 그러면, commit하는 동안 발생하는 document의 변경은 어떻게 해야 하나? 이들 중 어느 것도 잃지 않아야 한다.
Elasticsearch added a translog, or transaction log, which records every operation in Elasticsearch as it happens. With the translog, the process now looks like this:
Elasticsearch는 translog(transaction log) 를 추가했다. 이것은 Elasticsearch에서 발생하는 모든 연산을 기록한다. translog의 프로세스는 아래와 같다.
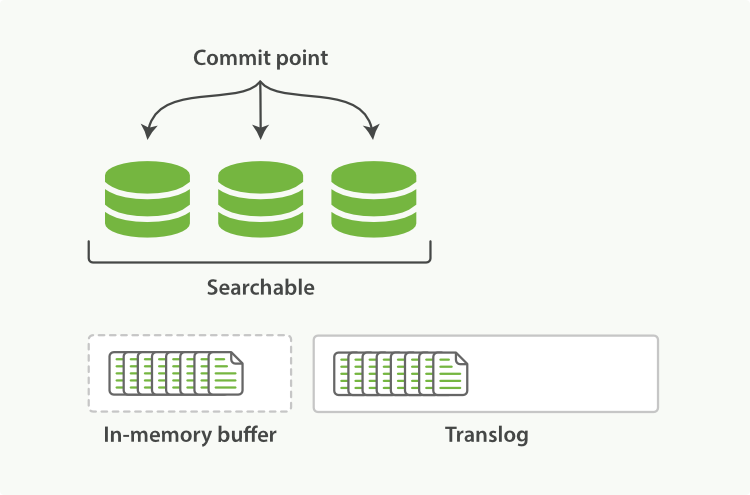
When a document is indexed, it is added to the in-memory buffer and appended to the translog, as shown in Figure 21, “새로운 document가 in-memory buffer에 추가되고, translog에 덧붙여진다.”.
document가 색인될 때, in-memory buffer에 추가된다. _그리고_, Figure 21, “새로운 document가 in-memory buffer에 추가되고, translog에 덧붙여진다.”에서 보듯이, translog에 덧붙여진다.
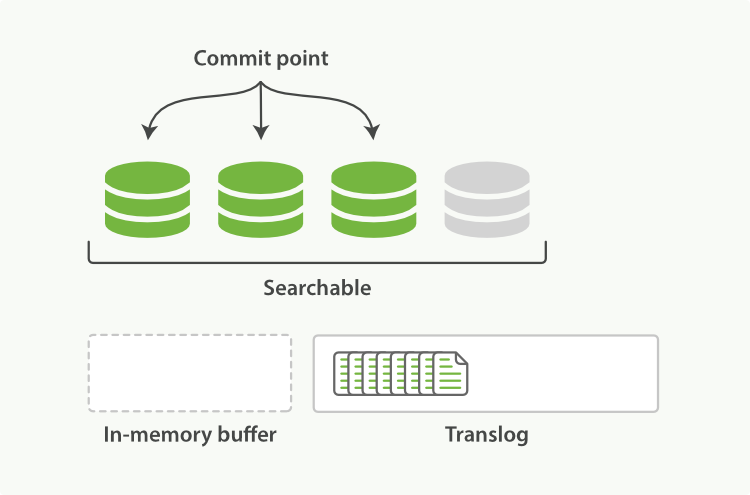
The refresh leaves the shard in the state depicted in Figure 22, “refresh후에 buffer는 지워지지만, translog는 지워지지 않는다.”. Once every second, the shard is refreshed:
refresh를 하면, shard는 Figure 22, “refresh후에 buffer는 지워지지만, translog는 지워지지 않는다.”의 상태가 된다. 매초마다 shard는 refresh된다.
The docs in the in-memory buffer are written to a new segment, without an
fsync.fsync없이, in-memory buffer에 있는 document는 새로운 segment에 기록된다.The segment is opened to make it visible to search.
검색 시에 보이게 하기 위해, segment가 열린다.
The in-memory buffer is cleared.
in-memory buffer는 지워진다.
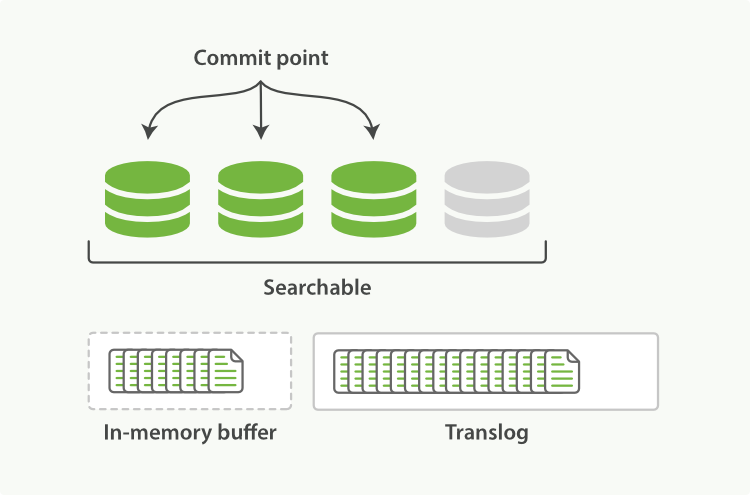
This process continues with more documents being added to the in-memory buffer and appended to the transaction log (see Figure 23, “translog는 document의 축적을 계속한다.”).
이 프로세스는 in-memory buffer에 추가되고, transaction log에 덧붙여진 더 많은 document와 함께 계속된다.(Figure 23, “translog는 document의 축적을 계속한다.” 참고)
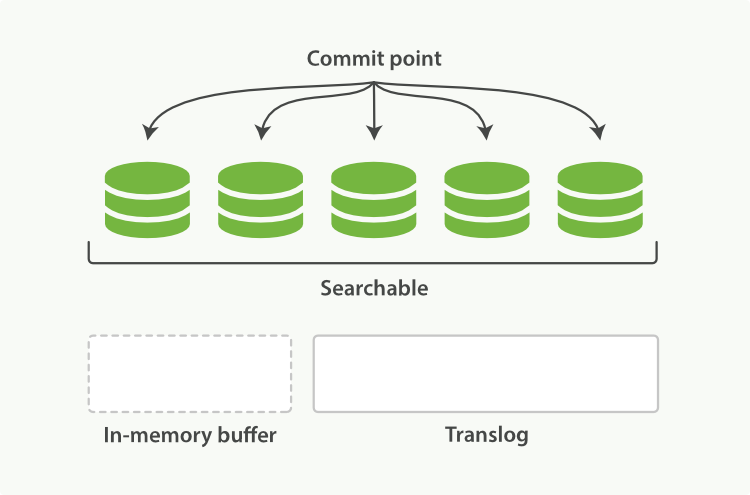
Every so often—such as when the translog is getting too big—the index is flushed; a new translog is created, and a full commit is performed (see Figure 24, “flush 후에, segment는 전부 commit되고, translog는 지워진다.”):
가끔, translog가 너무 커지는 경우, index는 flush된다. 새로운 translog가 생성되고, 전체 commit이 수행된다.(Figure 24, “flush 후에, segment는 전부 commit되고, translog는 지워진다.” 참고)
Any docs in the in-memory buffer are written to a new segment.
in-memory buffer에 있는 모든 document는 새로운 segment에 기록된다.
The buffer is cleared.
buffer는 지워진다.
A commit point is written to disk.
commit point는 디스크에 기록된다.
The filesystem cache is flushed with an
fsync.filesystem cache는
fsync를 통해 flush된다.The old translog is deleted.
기존의 translog는 지워진다.
The translog provides a persistent record of all operations that have not yet been flushed to disk. When starting up, Elasticsearch will use the last commit point to recover known segments from disk, and will then replay all operations in the translog to add the changes that happened after the last commit.
translog는 디스크에 아직 flush되지 않은, 모든 연산을 유지한 기록이다. 시작 시에, Elasticsearch는 알고 있는 segment를 디스크에서 복구하기 위해, 최근 commit point를 사용한다. 그리고, 마지막 commit후에 발생한 변경 사항을 추가하기 위해, translog에 있는 모든 연산을 다시 한다.
The translog is also used to provide real-time CRUD. When you try to retrieve, update, or delete a document by ID, it first checks the translog for any recent changes before trying to retrieve the document from the relevant segment. This means that it always has access to the latest known version of the document, in real-time.
translog는 또한 실시간 CRUD를 제공하기 위해, 사용되기도 한다. ID를 이용해 document를 읽고, 업데이트하고, 지우기를 시도하면, 관련 있는 segment에서 document를 가져오려고 시도하기 전에, 최근의 변경 사항을 translog에서 먼저 확인한다. 즉, 실시간으로, 항상 document의 가장 최근 버전을 액세스한다.
flush APIedit
The action of performing a commit and truncating the translog is known in Elasticsearch as a flush.Shards are flushed automatically every 30 minutes, or when the translog becomes too big. See thetranslog documentation for settings that can be used to control these thresholds:
commit을 수행하고, translog를 지우는 동작은, Elasticsearch에서 flush 라 알려져 있다. shard는 매 30분마다 자동으로, 또는 translog가 너무 크면 flush한다. 이 기준을 제어하는데 사용되는 설정은 translogdocumentation을 참조하자.
The flush API can be used to perform a manual flush:
The flush API는 수동으로 flush를 수행할 때 사용된다.
|
|
| 모든 indices를 flush하고, 반환하기 전에 모든 flush가 완료될 때까지 기다린다. |
You seldom need to issue a manual flush yourself; usually, automatic flushing is all that is required.
직접 수동으로 flush 할 필요는 거의 없다. 일반적으로 자동 flush로 충분하다.
That said, it is beneficial to flush your indices before restarting a node or closing an index. When Elasticsearch tries to recover or reopen an index, it has to replay all of the operations in the translog, so the shorter the log, the faster the recovery.
그렇지만, node를 다시 시작하거나 index를 닫기(closing index)전에, index를 flush하는 것이 유용하다. Elasticsearch가 index를 다시 열거나 복구할 때, translog의 모든 연산을 다시 한다. 따라서, log가 짧을수록, 복구는 더 빠르다.
'2.X > 1. Getting Started' 카테고리의 다른 글
| 1-11. Inside a Shard (0) | 2017.09.30 |
|---|---|
| 1-11-1. Making Text Searchable (0) | 2017.09.30 |
| 1-11-2. Dynamically Updatable (0) | 2017.09.30 |
| 1-11-3. Near Real-Time Search (0) | 2017.09.30 |
| 1-11-5. Segment Merging (0) | 2017.09.30 |